Introduction
MongoDB에 대규모 데이터를 저장하기 위해서는 Shard Cluster를 사용하게 됩니다.
데이터를 분산해서 저장할 수 있을 뿐만 아니라, 데이터의 증가가 예상되는 상황이라면 Scale out도 가능하기 때문입니다.
관련된 업무를 하다보니 Shard에 대한 개념을 조금 알고는 있었지만, 관련된 내용을 상세히 알 필요가 있다고 생각해서 공식 문서를 보고 공부를 했습니다.
하지만 공식 문서만 보고 파악하려했는데 여러 문서로 작성되어 있고, 항목들이 나뉘어져 찾아보기 어려웠습니다.
그래서 MongoDB의 Sharding에 대해 쉽게 알아볼 수 있도록 나름대로 재구성해보았습니다.
(mongos와 config server는 여기서 다루지 않습니다.)
- Sharding이 무엇인지
- 어떤 Sharding 방식이 있는지
- 그의 특징이 무엇인지
- 어떤 단점들이 있는지
- Shard key를 어떻게 구성하면 되는지
위의 내용들을 초심자(?) 관점으로 살펴보았습니다.
작성한 글에는 공식 문서 내용이 포함되어 있으며, 추가로 작성한 내용과 수정한 내용이 포함되어있습니다.
참고해서 봐주시면 좋겠습니다.
Objective
앞선 소개에서 대규모의 데이터를 저장하기 위해서는 Shard Cluster를 사용하게 된다고 말씀드렸습니다.
Shard Cluster가 무엇인지부터 이야기해보자면, 말 그대로 Shard로 구성된 Cluster를 의미합니다. 쉽게 이야기하면 Shard 여러개가 한 묶음이라는 거죠.
Cluster가 분산 데이터를 저장하기 위한 구성인 것을 생각한다면, Shard는 전체 데이터 셋을 가진 Cluster에서 일부분의 데이터셋을 저장하고 있겠다는 것을 유추해 볼 수 있습니다.
즉 Shard는 저장하고자 하는 전체 데이터셋 중에서 일부 데이터셋을 저장하고 있는 단위입니다.
개념적으로 보면 그렇고, Primary와 Secondary 역할로 나누어진 MongoDB들로 구성됩니다. MongoDB Replica Set이라고 보시면 됩니다.
MongoDB Sharding의 목적에 대해 이야기하기 위해서는 관련된 내용을 알 필요가 있다고 생각해서 Shard Cluster가 무엇인지, Shard가 무엇인지 간단히 적어보았습니다.
MongoDB Sharding 관련된 문서를 한번이라도 읽어보신적이 있으시다면 아시겠지만, Sharding의 목적은 Cluster의 Shard에 데이터를 고르게 분산하기 위함입니다.
고르게 분산 저장되어야 저장공간을 효과적으로 쓸 수 있을 뿐만 아니라, 부하가 고르게 분산될 수 있기 때문입니다. 이것이 바로 Scale out한 목적이기도 하고요.
Shard에 고르게 분산 되어야 MongoDB의 저장단위인 Chunk가 Shard내에서 고르게 분산될 수 있기 때문입니다.
Hashed Sharding, Ranged Sharding
MongoDB의 Sharding방식은 2가지가 존재합니다. Hashed Sharding과 Ranged Sharding입니다.
Hashed Sharding은 single field hash index 또는 compound hash index(4.4의 새로운 기능)를 샤드 키로 사용하여 샤딩된 클러스터에서 데이터를 분할하는 것을 말합니다.
아래의 그림이 Hashed Sharding을 직관적으로 표현하고 있습니다.
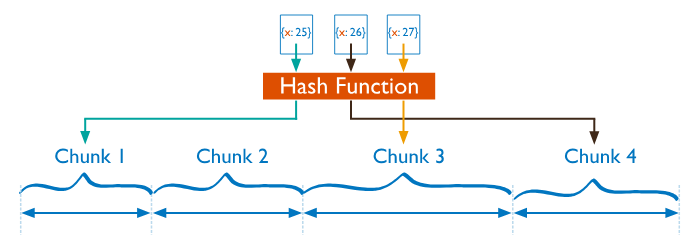
Ranged Sharding은 Shard Key 값에 의해 결정되는 인접한 범위로 데이터를 분할하는 것입니다. 이 방식에서 Shard Key값이 가까운(근접한) 문서는 동일한 청크 또는 샤드에 있을 가능성이 높습니다.
아래의 그림이 Ranged Sharding을 직관적으로 표현하고 있습니다.
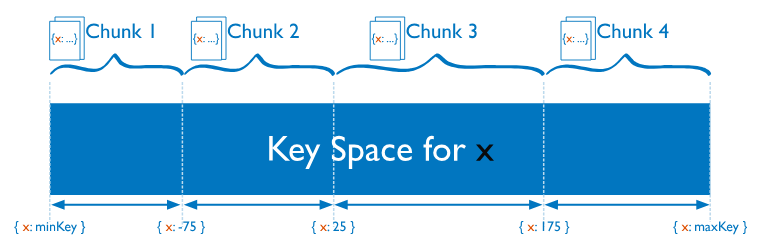
Hashed vs Ranged Sharding
각 Sharding 방식에 대해서 간단히 알아보았습니다. 상세한 내용은 뒤에서 더 설명하겠지만, 그전에 앞서 Shard Key에 따라 Hashed Sharding과 Ranged Sharding이 어떤 차이를 보여주는지 살펴보도록 하겠습니다.
순차적으로 증가하는 값을 가진 X라는 필드를 샤드키로 사용하는 컬렉션이 있다고 가정해보겠습니다. Ranged Sharding를 사용할때는 유입되는 Insert가 아래와 같이 분배가 됩니다.
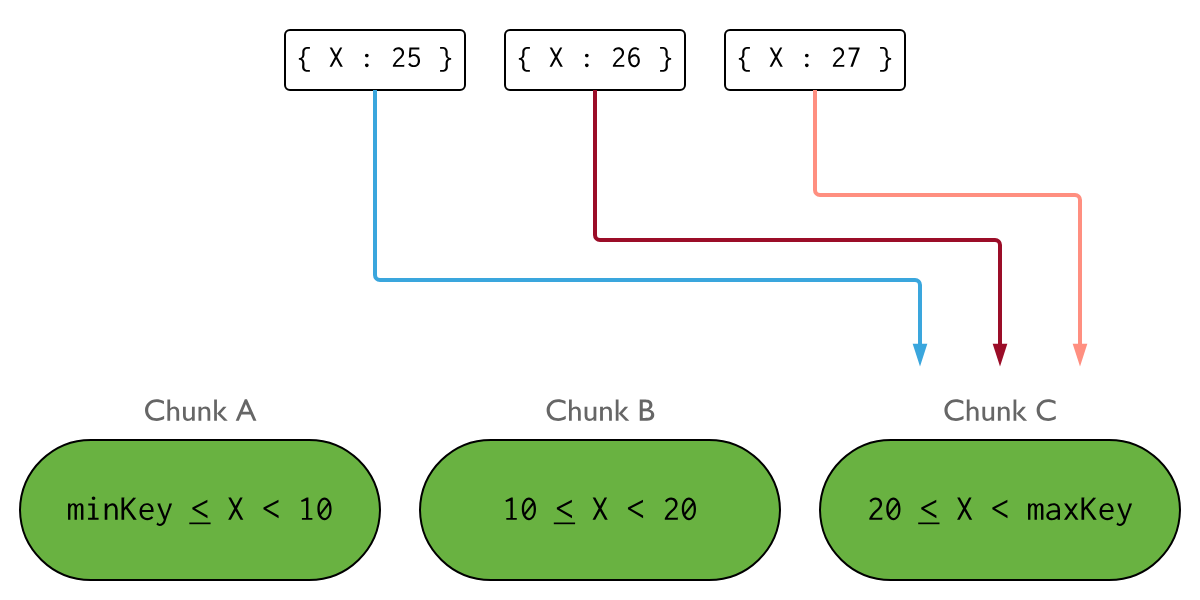
Chunk의 Upper bound를 MaxKey라고 합니다. 위의 그림에서 X는 항상 증가하기 때문에, MaxKey를 가지는 Chunk는 유입되는 대부분의 Write를 받습니다. 이는 Insert작업이 해당 Chunk(Chunk C)를 포함한 Single Shard에만 이루어집니다. 이는 Sharded Cluster에 분산 저장하는 이점을 감소시킵니다.
반면에 X에 대해 Hashed Index를 사용하면, 아래처럼 Insert의 분산이 됩니다.
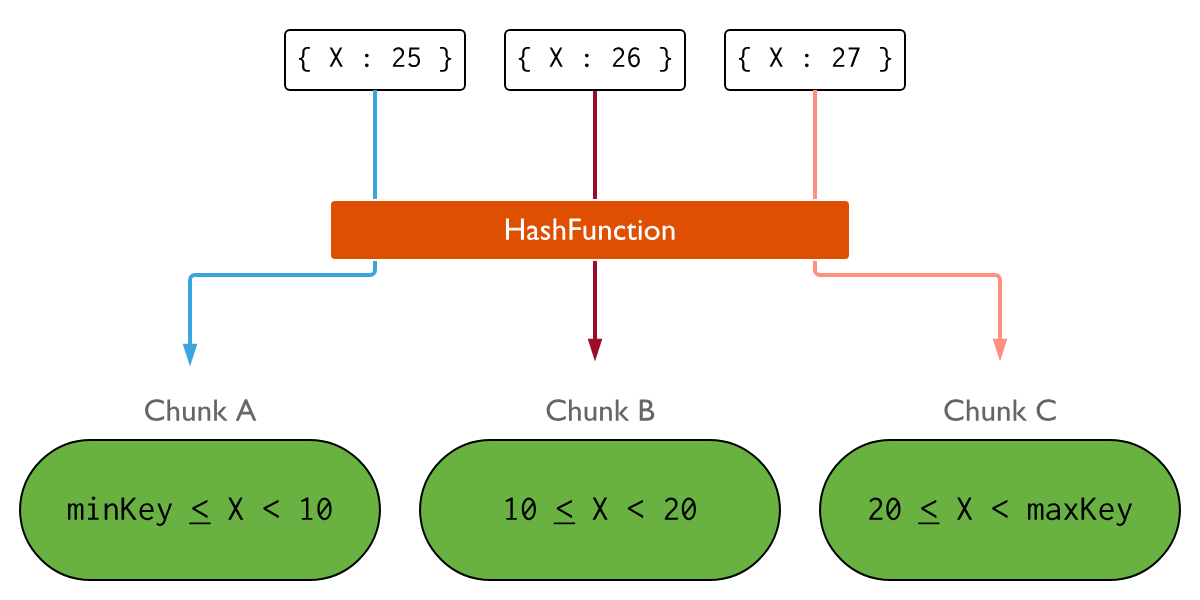
데이터가 공평하게 분산되었기 때문에, Insert는 Cluster 전체에 효율적으로 분산되었다고 볼 수 있습니다.
Shard Keys
https://www.mongodb.com/docs/manual/core/sharding-shard-key/
Shard Key는 문서가 어느 Shard로 분산될지 결정할때 사용되는 값 입니다.
Shard Key는 Single Indexed Field이거나 Cluster의 Shard 간에 컬렉션 문서의 분포를 결정하는 Compound Index가 적용되는 여러 필드입니다.
MongoDB는 Shard Key 값(또는 Hashed Shard Key 값)의 범위를 Shard Key 값(또는 Hashed Shard Key 값)이 겹치지 않는 범위로 나눕니다. 범위는 Chunk와 관련있으며, MongoDB는 Chunk를 Shard Cluster에 균등하게 분산시키려 노력합니다.
Shard Key Indexes
Sharded Collection은 Shard Key를 지원하는 Index가 필수입니다.
샤드 키는 단일 필드 인덱스 또는 복합 인덱스일 수 있습니다. 복합 인덱스의 경우, 샤드 키는 반드시 해당 복합 인덱스의 접두사(prefix)여야 합니다. 즉, 샤드 키를 구성하는 필드들이 복합 인덱스의 첫 번째 필드부터 순서대로 나와야 합니다.
예를 들어, { a: 1, b: 1, c: 1 }이라는 복합 인덱스가 있을 때, { a: 1 }, { a: 1, b: 1 }는 샤드 키가 될 수 있지만, { b: 1 }, { a: 1, c: 1 } 등은 샤드 키가 될 수 없습니다.
Unique Indexes
- 본문내용 : https://www.mongodb.com/docs/manual/core/sharding-shard-key/#unique-indexes
- 상세내용 : https://www.mongodb.com/docs/manual/core/index-unique/
MongoDB는 범위가 넓은 Shard Key Index에 고유성 제약 조건을 적용할 수 있습니다. Shard Key에 unique index를 사용함으로써, MongoDB는 Shard Key의 개별 구성 요소가 아닌 전체 키 조합에 고유성을 적용합니다.
Ranged Shard Collection의 경우 다음 인덱스만 고유할 수 있습니다
- 샤드 키의 인덱스
- 샤드 키가 접두사인 복합 인덱스
id필드가 샤드 키이거나 샤드 키의 접두사인 경우,_id인덱스는 전체 샤드 클러스터에 걸쳐 고유성을 보장합니다. 그렇지 않은 경우,_id인덱스는 각 샤드 내에서만 고유성을 보장합니다. 즉, 서로 다른 샤드에 동일한_id값을 가진 문서가 존재할 수 있습니다.- A Shard에 _id 값이 1, B Shard에 _id 값이 1 이 될 수 있다.
- 이 상황에서는 MongoDB는 Application에서 uniqueness를 강제할 것으로 기대한다.
Unique Index 제약은 다음을 의미합니다.
- 모든 unique index의 접두사가 shard key면 sharding이 가능하지만, 그게 아니라면 sharding할 수 없다.
- 이미 샤딩된 컬렉션의 경우 다른 필드에 고유 인덱스를 만들 수 없습니다.
- unique index는 인덱싱된 필드가 누락된 문서에 대해 null 값으로 저장합니다. 즉, 누락된 인덱스 필드는 null 인덱스 키 값인 다른 인스턴스로 취급됩니다. 자세한 내용은 고유 단일 필드 인덱스에 누락된 문서 필드를 참조하세요.
샤드 키 값에 고유성을 적용하려면, 고유 매개변수를 sh.shardCollection() 메서드에 true로 전달합니다.
- 컬렉션이 비어 있는 경우, 그러한 인덱스가 아직 존재하지 않는 경우 sh.shardCollection()는 Shard Key에 Unique Index를 생성합니다.
- 컬렉션이 비어 있지 않은 경우, sh.shardCollection()을 사용하기 전에 인덱스를 먼저 생성해야 합니다.
Shard key가 접두사인 unique compound index를 가질 수 있지만, unique 매개변수를 사용하는 경우 컬렉션에 Shard key에 있는 unique index가 있어야 합니다.
Hashed Index에는 unique constraint를 지정할 수 없습니다.
Hashed Sharding
Sharding on a Single Field Hashed Index
- Hashed Sharding은 샤드 키의 해시 값을 기준으로 데이터를 분산시킵니다.
- “targeted operations vs Broadcast Operations”
- targeted operations : 쿼리가 샤드 키를 포함하고 있어, MongoDB가 특정 샤드(들)로만 쿼리를 라우팅할 수 있는 경우입니다. 이는 효율적인 쿼리 처리를 가능하게 합니다.
- broadcast operations : 쿼리가 샤드 키를 포함하지 않거나, 샤드 키만으로는 쿼리를 라우팅할 샤드를 특정할 수 없는 경우입니다. 이 경우 MongoDB는 모든 샤드에 쿼리를 보내고 결과를 취합해야 하므로, 덜 효율적입니다.
- Hashed Sharding은 샤드 키 값의 해시를 기반으로 데이터를 분산하기 때문에, 범위 쿼리(ranged query)를 수행할 때는 샤드 키 값이 특정 범위에 속하는 문서를 가진 샤드를 정확히 알 수 없습니다. 따라서 mongos는 범위 쿼리에 대해 broadcast operation을 수행할 가능성이 높습니다.
- 샤드 키 값이 랜덤하게 분산되기 때문에 데이터가 골고루 분산될 수 있습니다.
- mongos는 ranged query가 주어지면 broadcast operations을 수행할 가능성이 높습니다.
- mongos는 단일 샤드와 동일하게 일치하는 쿼리를 타깃팅할 수 있습니다.
Sharding on a Compound Hashed Index
MongoDB는 4.4버전부터 single hashed field로 compound indexes 생성하는 것을 지원합니다.
복합 해시 인덱스를 만들려면 인덱스를 만들 때 단일 인덱스 키의 값으로 hashed를 지정해야 합니다.
복합 해시 인덱스는 복합 인덱스에 있는 단일 필드의 해시 값을 계산하며, 이 값은 인덱스의 다른 필드와 함께 샤드 키로 사용됩니다.
Compound hash sharding은 zone sharding과 같은 기능을 지원하는데, 해시되지 않은 접두사(즉, 첫 번째) 필드는 영역 범위를 지원하고 해시된 필드는 샤딩된 데이터의 보다 균일한 분포를 지원합니다. 복합 해시 샤딩은 또한 단조롭게 증가하는 필드와 관련된 데이터 배포 문제를 해결하기 위해 해시 접두사가 있는 샤드 키를 지원합니다.
zone sharding의 주 장점은 “해시되지 않은 접두사” 필드를 기준으로 특정 샤드만을 타겟팅할 수 있어, 샤드 전역 브로드캐스트를 피할 수 있다는 것입니다.
Hashed Sharding Shard Key
선택한 shard key는 good cardinality를 가지거나 다른 큰 숫자를 가져야 한다.
해시 키는 ObjectId 값이나 타임스탬프처럼 단조롭게(단조증가) 변경되는 필드가 있는 샤드 키에 이상적입니다.
기본 _id 필드에 ObjectId 값만 포함되어 있다고 가정하는 것이 좋은 예입니다.
Shard the Collection
sh.shardCollection()함수를 사용하려면, collection의 full namespace와 shard key로 사용하기 위한 target hashed index를 명시합니다.
|
|
compound hased index로 Shard하려면, collection의 full namespace와 shard key로 사용하기 위한 target compound hashed index를 작성합니다.
|
|
Ranged Sharding
Range-based sharding은 인접 범위의 데이터를 나누며, shard key에 따라 결정됩니다.
이 모델에서 인접한 shard key 값을 가진 문서는 같은 chunk에 들어가거나 shard에 들어가게 됩니다. 이는 인접한 범위안에 있는 문서를 읽는 쿼리를 효율적이게 만듭니다.
하지만 shard key선택에 따라 read와 write성능이 감소할 수 있습니다.
- Ranged Sharding에서 샤드 키 선택이 잘못되면, 특정 샤드에 읽기/쓰기 연산이 집중되는 핫스팟(hotspot) 현상이 발생할 수 있습니다. 예를 들어, 단조롭게 증가하는(monotonically increasing) 샤드 키를 사용하면, 대부분의 쓰기 연산이 최댓값(MaxKey)을 가진 청크가 있는 샤드로 집중될 수 있습니다.
- 이를 방지하기 위해 샤드 키의 카디널리티(cardinality), 빈도(frequency), 단조성(monotonicity) 등을 고려하여 신중하게 샤드 키를 선택해야 합니다.
범위 기반 샤딩은 해시 샤딩에 필요한 옵션이나 영역과 같은 다른 옵션이 구성되지 않은 경우 기본 샤딩 방법입니다.
Shard Key Selection
Ranged Sharding은 Shard key가 아래의 특성들들을 보일때 가장 효율적입니다.
- Large Shard Key Cardinality
- Low Shard key Frequency
- Non-Monotonically Changing Shard keys
Key(X)가 큰 범위를 가지고, 적은 frequency, non-monotonic rate(단조롭지 않은 속도)로 바뀐다면, insert의 분포는 아래의 그림과 같습니다.
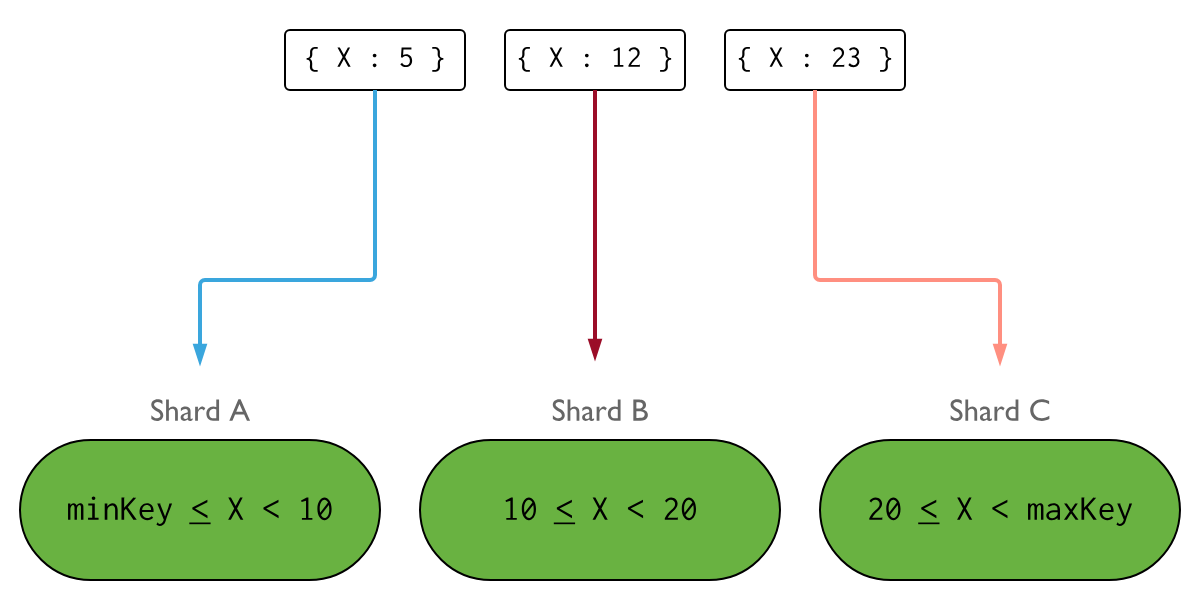
Shard Key Cardinality
cardinality 용어 정리 : https://www.mongodb.com/docs/manual/reference/glossary/#std-term-cardinality
shard key의 cardinality는 밸런서가 생성가능한 최대 chunk의 개수를 결정합니다. 가능하다면, 높은 cardinality를 가진 shard key를 선택해야 합니다. 낮은 cardinality를 가진 shard key는 cluster내에 horizaontal scaling의 효과를 감축시킵니다.
각각의 고유한 샤드 키 값은 주어진 시간에 하나의 청크범위에만 존재할 수 있습니다. continent 필드가 있는 사용자 데이터가 포함된 데이터 세트를 생각해 봅시다. continent을 기준으로 샤딩을 선택한 경우, 샤드 키의 Cardinality는 7이 됩니다. Cardinality가 7이라는 것은 샤딩된 클러스터 내에 각각 하나의 고유한 샤드 키 값을 저장하는 청크가 7개 이상 있을 수 없다는 뜻입니다. 따라서 클러스터의 유효 샤드 수도 7개로 제한되며, 샤드를 7개 이상 추가해도 아무런 이점이 없습니다.
아래 이미지에서는 sharded cluster에서 X라는 필드를 shard key로 사용하였습니다. 만약 X가 낮은 cardinality를 가진다면, insert의 분포는 아래와 같이 될 것입니다.
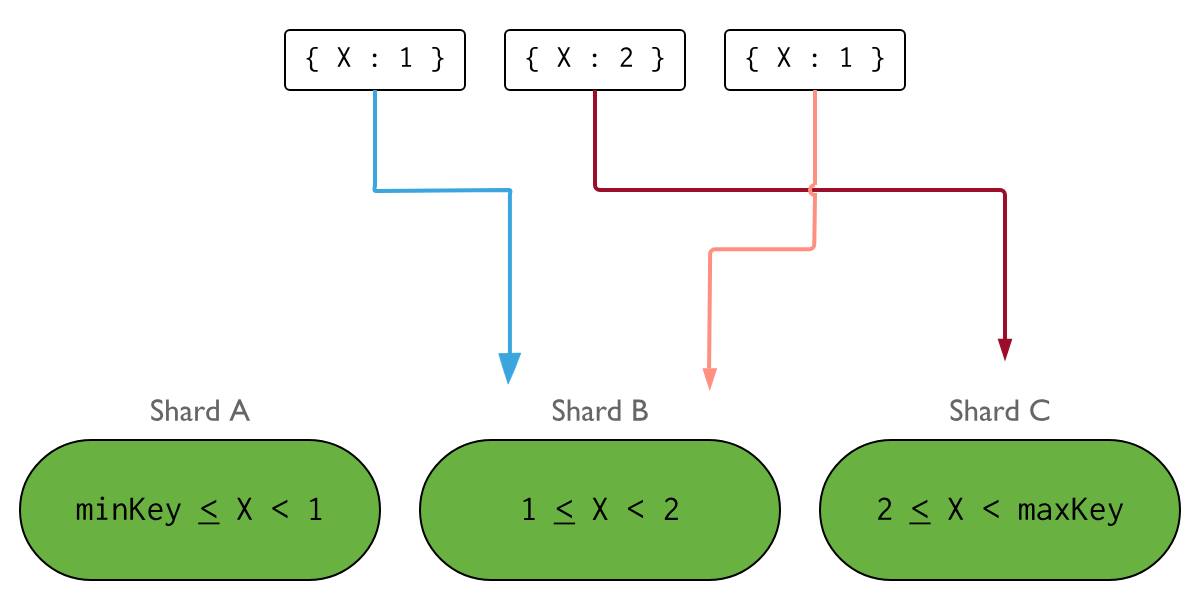
데이터 모델에 Cardinality가 낮은 키에 대한 샤딩이 필요한 경우, 인덱싱된 필드 복합체를 사용하여 Cardinality를 높이는 것을 고려하세요.
카디널리티가 높은 샤드 키는 그 자체로 샤드 클러스터 전체에 데이터의 고른 분포를 보장하지 않습니다. frequency of shard key와 monotonically potential for changing shard key values 또한 데이터의 분포에 공헌합니다.
Shard Key Frequency
샤드 키의 빈도는 주어진 샤드 키 값이 데이터에서 얼마나 자주 발생하는지를 나타냅니다. 대부분의 문서가 가능한 샤드 키 값의 하위 집합만 포함하는 경우, 해당 값의 문서를 저장하는 청크가 클러스터 내에서 병목 현상이 발생할 수 있습니다. 또한, 이러한 청크가 커지면 더 이상 분할할 수 없어 분할 불가능한 청크가 될 수 있습니다. 이렇게 되면 클러스터 내에서 수평적 확장의 효과가 감소합니다.
다음 이미지는 필드 X를 샤드 키로 사용하는 샤드 클러스터를 보여줍니다. X에 대한 값의 하위 집합이 높은 빈도로 발생하는 경우, 삽입 분포는 다음과 비슷하게 보일 수 있습니다:
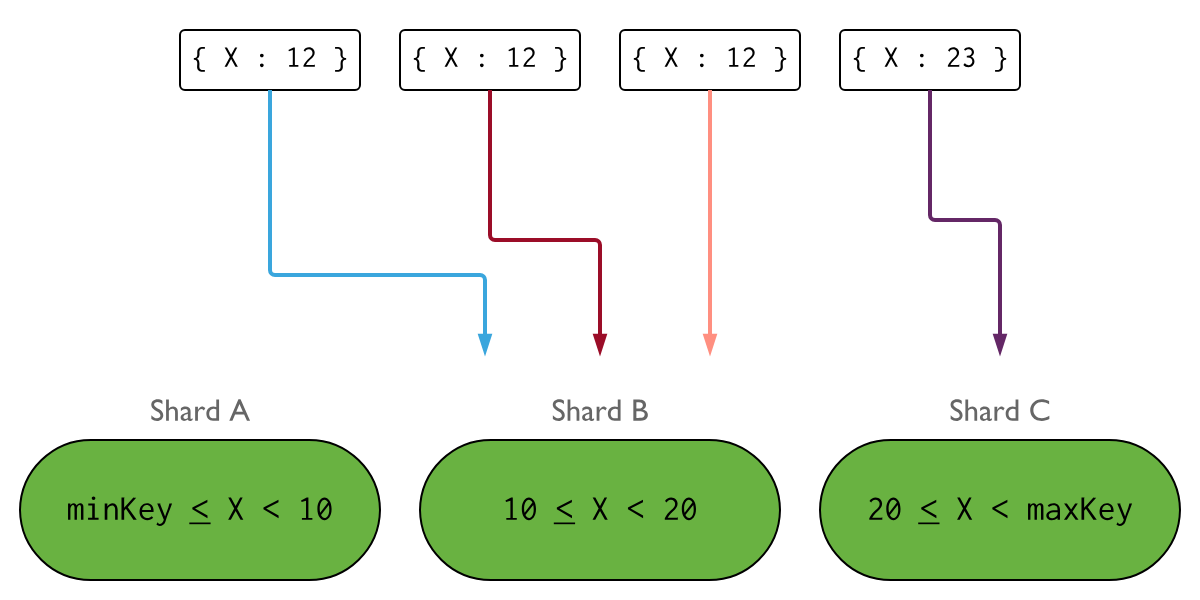
데이터 모델에 높은 빈도의 값을 갖는 키에 대한 샤딩이 필요한 경우, 고유하거나 낮은 빈도의 값을 사용하는 복합 인덱스를 사용하는 것이 좋습니다.
빈도가 낮은 샤드 키는 그 자체로는 샤드 클러스터 전체에 데이터의 고른 분포를 보장하지 않습니다.
앞서 말한 내용처럼 shard key에 대한 cardinality와 potential for monotonically changing shard key values 또한 데이터 분포에 영향을 기여합니다.
Monotonically Changing Shard Keys
단조롭게 증가하거나 감소하는 값의 샤드 키는 클러스터 내의 단일 청크에 인서트를 배포할 가능성이 더 높습니다.
이는 모든 클러스터에 MaxKey의 상한을 가진 범위를 캡처하는 청크가 있기 때문에 발생합니다. maxKey는 항상 다른 모든 값보다 높은 값으로 비교됩니다. 마찬가지로, MinKey의 하한을 가진 범위를 캡처하는 청크가 있습니다. minKey는 항상 다른 모든 값보다 낮은 값으로 비교됩니다.
샤드 키 값이 항상 증가하는 경우, 모든 새로운 삽입은 maxKey를 상한으로 하여 청크로 라우팅됩니다. 샤드 키 값이 항상 감소하는 경우, 모든 새로운 삽입은 minKey를 하한으로 하는 청크로 라우팅됩니다. 해당 청크를 포함하는 샤드가 쓰기 작업의 병목 현상이 발생합니다.
데이터 배포를 최적화하기 위해 글로벌 maxKey(또는 minKey)를 포함하는 청크는 동일한 샤드에 유지되지 않습니다. 청크가 분할되면 maxKey(또는 minKey) 청크가 포함된 새 청크는 다른 샤드에 위치하게 됩니다.
다음 이미지는 X 필드를 샤드 키로 사용하는 샤드 클러스터를 보여줍니다. X 값이 단조롭게 증가하는 경우, 삽입의 분포는 다음과 유사하게 보일 수 있습니다.
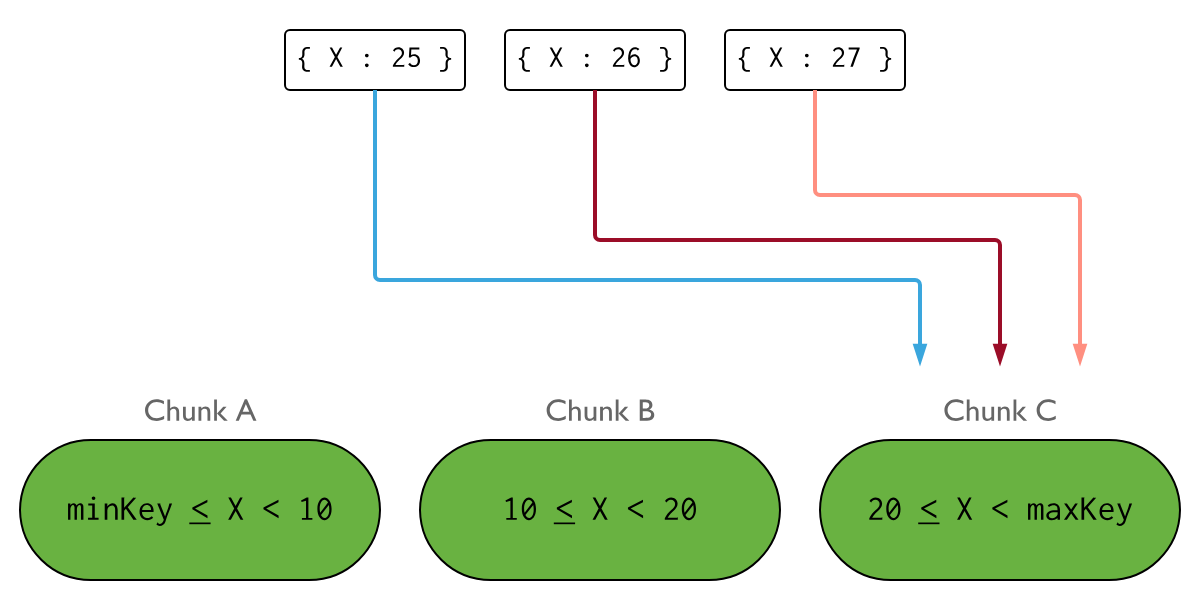
샤드 키 값이 단조롭게 감소하는 경우, 모든 삽입은 대신 청크 A로 라우팅됩니다.
데이터 모델에 단조롭게 변경되는 키에 대한 샤딩이 필요한 경우, 해시 샤딩을 사용하는 것이 좋습니다.
단조롭게 변경되지 않는 샤드 키는 그 자체로는 샤드 클러스터 전체에 데이터의 고른 분포를 보장하지 못합니다. shard key에 대한 cardinality와 frequency가 data의 분포에 공헌합니다.
Sharding Query Patterns
이상적인 샤드 키는 데이터를 샤드 클러스터 전체에 고르게 분산시키는 동시에 일반적인 쿼리 패턴을 용이하게 합니다. 샤드 키를 선택할 때는 가장 일반적인 쿼리 패턴과 특정 샤드 키가 이러한 패턴을 커버하는지 여부를 고려하세요.
샤드 클러스터에서, 몽고는 쿼리에 샤드 키가 포함된 경우 관련 데이터가 포함된 샤드로만 쿼리를 라우팅합니다.
쿼리에 샤드 키가 포함되지 않은 경우, 쿼리는 평가를 위해 모든 샤드로 브로드캐스트됩니다. 이러한 유형의 쿼리를 분산 수집 쿼리라고 합니다. 각 요청에 대해 여러 샤드를 포함하는 쿼리는 효율성이 떨어지며 클러스터에 더 많은 샤드가 추가될 때 선형적으로 확장되지 않습니다.
대량의 데이터에 대한 집계 쿼리의 경우, 모든 샤드에 쿼리를 병렬로 실행하는 분산 수집(scatter-gather) 방식이 유용할 수 있습니다. 왜냐하면 각 샤드가 데이터의 일부를 처리하고, 최종적으로 결과를 취합하여 반환하기 때문에, 단일 샤드에 부하가 집중되는 것을 방지하고 전체적인 처리 속도를 향상시킬 수 있기 때문입니다.
Shard on Collection
컬렉션의 전체 네임스페이스와 샤드 키로 사용할 대상 인덱스 또는 복합 인덱스를 지정하여 sh.shardCollection() 메서드를 사용합니다.
|
|
Sharding troubleshooting shard keys
Jumbo Chunks
청크의 크기가 설정된 최대 크기를 초과하여 더 이상 분할할 수 없는 청크를 말합니다. 이는 샤드 키의 카디널리티가 낮거나, 특정 샤드 키 값의 빈도가 너무 높을 때 발생할 수 있습니다.
Uneven Load Distribution(Hot Shard, Hot Chunk)
클러스터에 고르지 않은 로드 분배가 발생하는 경우, 샤드 키가 단조롭게 증가하는지 확인하세요. 단조롭게 증가하는 필드인 샤드 키는 읽기 및 쓰기 분포가 고르지 않게 됩니다.
주문_id 필드에 샤딩된 주문 컬렉션을 생각해 봅시다. order_id는 주문이 있을 때마다 하나씩 증가하는 정수입니다.
- 새 문서는 일반적으로 동일한 샤드와 청크에 기록됩니다. 쓰기를 받는 샤드와 청크를 핫 샤드와 핫 청크라고 합니다. 핫 샤드는 시간이 지남에 따라 변경됩니다. 청크가 분할되면 핫 청크는 데이터 배포를 최적화하기 위해 다른 샤드로 이동합니다.
- 사용자가 모두 같은 샤드에 있는 최근 주문과 상호작용할 가능성이 높다면, 최근 주문이 포함된 샤드가 대부분의 트래픽을 받게 됩니다.
Decreased Query Performance Over Time
시간이 지남에 따라 쿼리 성능이 저하되는 경우, 클러스터가 분산 수집 쿼리를 수행하고 있을 수 있습니다.
클러스터가 분산 수집 쿼리를 수행하고 있는지 평가하려면 가장 일반적인 쿼리에 샤드 키가 포함되어 있는지 확인하세요.
쿼리에 샤드 키를 포함하는 경우, 샤드 키가 해시되어 있는지 확인하세요. 해시 샤딩을 사용하면 문서가 샤드 키 필드 값의 오름차순 또는 내림차순으로 저장되지 않습니다. 오름차순 또는 내림차순으로 저장되지 않은 데이터에 대해 샤드 키 값에 대한 범위 기반 쿼리를 수행하면 분산 수집 쿼리의 성능이 저하됩니다. 샤드 키에 대한 범위 기반 쿼리가 일반적인 액세스 패턴인 경우, 컬렉션을 리샤딩하는 것이 좋습니다.
나름 정리
- hashed sharding
- 데이터 분포는 고르게 된다.
- 오름차순 내림차순 shard key라 하더라도, 동일한 chunk에 들어가는 보장이 없다. 오히려 분산될거다.
- ranged query를 사용하면 모든 shard에 쿼리를 실행해야하기 때문에, 성능저하가 발생할거다. shard key를 통해 shard가 특정가능하면, 해당 shard에만 쿼리를 실행한다.
- hashed single field index나 hashed single field가 포함된 compound index로 hashed sharding이 이용가능하다.
- ranged sharding
- id 값의 범위를 나누어 분포된다. 따라서 인접한 id는 동일한 chunk에 들어갈 확률이 높다.
- 오름차순 내림차순으로 증가 감소하는 id의 경우에 chunk에 부담을 줄 수 있어 조심해야한다.
- shard key선택하는 기준
- high cardinality : shard key에 대한 중복성이 없고, unique성이 크면 좋겠다.
- low frequency : shard key의 값이 자주 나오면 안된다.
- Non-Monotonically Changing Shard keys : id값이 단조증가 또는 단조감소일경우는 hash가 낫다.
- 그냥 shard key 넣어주면 되는듯?
- shard key 선택 기준
- cardinality가 충분히 높아야 한다.
- 단조로우면 안된다.
- 자주 질의되는(쿼리조건에 자주 등장하는) 필드가 좋다.